
노트 1: Wikidocs 딥 러닝을 이용한 자연어 처리 입문
Updated:
딥 러닝을 이용한 자연어 처리 입문을 읽고 내용을 요약한다.
- 자세한 응용 코드는 제외
- 주요 내용과 용어, 따라하기 실패 등을 기록
1. 자연어 처리란?
- 자연어 처리 응용 분야
- 음성 인식, 내용 요약, 번역, 사용자 감성 분석
- 텍스트 분류 작업 (스팸 메일 분류, 뉴스 기사 카테고리 분류)
- 질의 응답 시스템, 챗봇
- 책에서 다룰 내용
- 전처리 방법 (preprocessing)
- 딥 러닝 이전 통계 기반 모델
- 딮 러닝을 이용한 자연어 처리 지식
- 책에서 사용하는 파이썬 패키지
- Anaconda 설치: Numpy, Pandas, Jupyter notebook, IPython, Scikit-learn, matplotlib, seaborn, nltk
- third-party: Tensorflow, Keras, Gensim, KoNLPy
- anaconda에서 파이썬 패키지 최신 버전으로 업데이트
$ conda update -n base conda
$ conda update --all
Tensorflow 설치
Anaconda Prompt를 관리자 권한으로 열어서 설치 할 것
$ pip install tensorflow # 당시 최신 버전 2.1.0
tensorflow가 설치는 되지만, import 하는 경우 아주 많은 메세지와 함께 ImportError가 발생했는데, 중간 메세지가 failed to load the native tensorflow runtime 이여서 검색해 보니
- 낮은 버전을 설치하라고 하거나 (2019-05-04)
- 강제 재설치 (2018-10-01)
를 해보라는 글이 있어서 먼저 강제 재설치를 해보았다.
$ pip install tensorflow --upgrade --force-reinstall
강제 재설치를 했으나 또다시 failed to load the native tensorflow runtime 메세지가 포함된 에러가 발생했다.
이번에는 낮은 버전 설치 시도를 해보았다.
$ pip install tensorflow==2.0.0
일단은 2.0.0을 설치하니까 ImportError 문제가 해결 된 것 같기도하다.
$ ipython
In [1]: import tensorflow as tf
In [2]: tf.__version__
Out[2]: '2.0.0'
Keras, Gensim 설치
$ pip install keras # 최신 2.3.1
$ pip install gensim # 최신 3.8.1
둘 다 이상 없이 설치 완료되었다.
NLTK Data 설치
Anaconda에 이미 nltk가 설치되어 있다. nltk를 import 하고 nltk.download() 입력하면 NLTK Downloader 창이 뜨는데 뭘 다운로드 해야 되는지 몰라서 그냥 All 을 선택하였다. 다운로드는 꾀 오래 걸린다. 그리고 중간에 ‘<urlopen error [WinError 10060] 연결된 구성원으로부터 응답이 없어 연결하지 못했거나, 호스트로부터 응답이 없어 연결이 끊어졌습니다>’ 라는 메세지와 함께 다운로드가 중단된다. NLTK Downloader를 닫은 후 다시 열어서 다운로드를 다시 시작하였다. 그런데 생각해보니 그냥 그때그때 필요한 데이터를 선택적으로 다운로드 하는게 더 나을 것 같다는 생각이 들었다.
KoNLPy 설치
$ pip install konlpy # 최신 0.5.2
KoNLPy는 잘 설치된다. 그리고 책에서 언급하는 JDK 오류가 발생하지 않았으므로 우선 JDK 관련 부분은 그냥 넘어간다.
이 후 konlpy의 Okt를 사용할 때 JVMNotFoundException이 발생하였다. 그래서 JDK를 설치하기로 한다. Java SE Downloads로 가면 Java SE 13.0.2, Java SE 11.0.6 (LTS), Java 8u241 이 있다. 뭘 설치해야 현재 설치된 KoNLPy와 호환이 잘 될지 알 수 없어서 우선 Java SE 13.0.2를 설치해 보았다. jdk-13.0.2_windows-x64_bin.exe를 다운 받고 설치하였다. 이후 환경변수 JAVA_HOME로 C:\Program Files\Java\jdk-13.0.2 등록하였다.
JPype를 설치 안하면 KoNLPy를 사용할 때 RuntimeError: java.lang.ClassNotFoundException: org.jpype.Utility가 발생했다. 그래서 JPype도 설치하기로 했다. 현재 사용하는 Anaconda의 Python 버전이 3.7이고 운영체제가 64비트 이므로 JPype 다운로드에서 JPype1-0.7.1-cp37-cp37m-win_amd64.whl를 다운받고 $ pip install JPype1-0.7.1-cp37-cp37m-win_amd64.whl 명령으로 설치하였다.
그리고 다시 KoNLPy의 Okt 사용 테스트를 하면 이번에는 TypeError: No matching overloads found for constructor java.lang.Boolean(bool), options are: ... 에러가 발생한다.
연습해보기 되게 어렵네… 우선 KoNLPy 부분은 넘어가기로 한다. (2020-01-28 18:03)
판다스 프로파일링
- EDA (Exploratory Data Analysis, 탐색적 데이터 분석)
- 설치:
pip install -U pandas-profiling - download: span.csv
import pandas as pd
import pandas_profiling
data = pd.read_csv(r'workdir/spam.csv',encoding='latin1')
pr = data.profile_report()
pr.to_file('./pr_report.html')
Pandas Explratory Data Analysis: Data Profiling with one single command
머신 러닝 워크플로우
- 수집 (Acquisition): 말뭉치 또는 corpus
- 점검 및 탐색 (Inspection and exploration): 탐색적 데이터 분석 (EDA)
- 전처리 및 정제 (Preprocessing and Cleaning): 토큰화, 정제, 정규화, 불용어 제거
- 모델링 및 훈련 (Modeling and Training): Training, Validation, Testing
- 평가 (Evaluation)
- 배포 (Deployment)
2. 텍스트 전처리 (Text preprocessing)
1) 토큰화 (Tokenization)
- 토큰화: corpus를 의미 있는 단위인 토큰으로 나누는 것
from nltk.tokenize import word_tokenize, WordPunctTokenizerfrom tensorflow.keras.preprocessing.text import text_to_word_sequence
- Penn Treebank Tokenization: 표준으로 쓰이고 있는 토큰화 규칙 중 하나
- 규칙 1. 하이푼으로 구성된 단어는 하나로 유지한다.
- 규칙 2. doesn’t와 같이 아포스트로피로 ‘접어’가 함께하는 단어는 분리해준다.
from nltk.tokenize import TreebankWordTokenizer
-
문장 토큰화 (Sentence Tokenization): 문장 단위 토큰화, 문장 분류 (sentence segmentation) 라고도 부름
from nltk.tokenize import sent_tokenize
-
KSS (Korean Sentence Splitter) 설치 문제
- 설치 에러 발생
- 이진 분류기 (Binary Classifier): 문장 토큰화에서 마침표 처리를 두 개의 클래스로 분류
- 마침표가 단어의 일부일 경우. 예) Ph.D.
- 마침표가 문장의 구분자일 경우
- 영어의 경우 영어 약어 사전 참고
- How to Split Sentences 참고
- 한국어에서의 토큰화의 어려움
- 어절 토큰화는 단어 토큰화가 아님
- 형태소 (morpheme) 토큰화가 중요
- 자립 형태소: 접사, 어미, 조사와 상관없이 자립하여 사용할 수 있는 형태소. 체언 (명사, 대명사, 수사), 수식언 (관형사, 부사), 감탄사 등
- 의존 형태소: 다른 형태소와 결합하여 사용되는 형태소. 접사, 어미, 조사, 어간
- 띄어쓰기가 지켜지지 않음
- 품사 태깅 (Part-of-speech tagging)
-
단어 토큰화 과정에서 해당 단어가 어떤 품사로 쓰였는지 태깅
-
영어의 경우 NLTK Penn Treebank POG Tags
from nltk.tag import pos_tag
-
한국어의 경우 KoNLPy 형태소 태깅
from konlpy.tag import Okt- 또다른 한국어 형태소 분석기: Okt(Open Korea Text), 메캅(Mecab), 코모란(Komoran), 한나눔(Hannanum), 꼬꼬마(Kkma)
-
KoNLPy Okt 사용 시 문제
아래 코드는 KoNLPy Okt를 사용할 때 TypeError: No matching overloads found for constructor java.lang.Boolean(bool), options are:... 에러가 발생해서 실습해보지 못 했다. (2020-01-28 18:06)
from konlpy.tag import Okt
okt = Okt()
print(okt.morphs(r"열심히 코딩한 당신, 연휴에는 여행을 가봐요"))
print(okt.pos("열심히 코딩한 당신, 연휴에는 여행을 가봐요"))
print(okt.nouns("열심히 코딩한 당신, 연휴에는 여행을 가봐요"))
KKma 을 사용할 때도 TypeError: No matching overloads found for kr.lucypark.kkma.KkmaInterface.morphAnalyzer(str), options are:... 에러가 발생한다.
from konlpy.tag import Kkma
kkma=Kkma()
print(kkma.morphs("열심히 코딩한 당신, 연휴에는 여행을 가봐요"))
print(kkma.pos("열심히 코딩한 당신, 연휴에는 여행을 가봐요"))
print(kkma.nouns("열심히 코딩한 당신, 연휴에는 여행을 가봐요"))
2) 정제 (Cleaning) and 정규화 (Normalization)
토큰화 작업 전 후에 텍스트 데이터를 용도에 맞게 정제 (노이즈 데이터 제거) 및 정규화 (표현 방법이 다른 언어들을 통합시켜 같은 단어로 만듬)를 한다. 정제와 정규화 종류는
- 규칙에 기반한 표기가 다른 단어 통합. ex) USA와 US, uh-huh와 uhhuh 등
- 대, 소문자 통합
- 불필요한 단어 제거
- 등장 빈도가 적은 단어
- 길이가 짧은 단어
3) 어간 추출 (Stemming) and 표제어 추출 (Lemmatization)
-
표제어 추출: 단어가 다른 형태를 가지더라도 뿌리 단어를 찾아서 개수를 줄일 수 있는지 판단
- ex) am, are, is > be
- 표제어 (Lemma): 기본 사전형 단어 정도의 의미
- 표제어 추출을 하는 가장 섬세한 방법은 단어의 형태학적 파싱을 먼저 진행하는 것
- 형태학 (morphology): 형태소로 부터 단어를 만들어 가는 학문
- 형태소 (morpheme): 의미를 가진 가장 작은 단위
- 어간 (stem): 단어의 의미를 담고 있는 단어의 핵심 부분
- 접사 (affix): 단어에 추가적인 의미를 주는 부분
from nltk.stem import WordNetLemmatizer
- 어간 추출
- Porter 알고리즘:
from nltk.stem import PorterStemmer - 랭커스터 스태머(Lancaster Stemmer) 알고리즘:
from nltk.stem import LancasterStemmer
- Porter 알고리즘:
- 한국어에서의 어간 추출
- 5언 9품사 중 용언인 동사와 형용사는 어간 (stem)과 어미 (ending)의 결합으로 구성, 활용 (conjugation) 된다.
- 어간 (stem): 용언을 활용할 때 원칙적으로 모양이 변하지 않는 부분. 활용에서 어미에 선행하는 부분. 때론 어간의 모양도 바뀔 수 있음 (예: 긋다, 긋고, 그어서, 그어라)
- 어미 (ending): 용언의 어간 뒤에 붙어서 활용하면서 변하는 부분. 여러 문법적 기능을 수행
- 활용 (conjugation): 용언의 어간(stem)이 어미(ending)를 가지는 것
- 규칙 활용: 어간이 어미를 취할 때, 어간의 모습이 일정 (잡/어간 + 다/어미)
- 불규칙 활용: 어간이 어미를 취할 때, 어간이나 어미의 모습이 변함
- 5언 9품사 중 용언인 동사와 형용사는 어간 (stem)과 어미 (ending)의 결합으로 구성, 활용 (conjugation) 된다.
4) 불용어 (Stopword)
- 자주 등장하지만 분석에 거의 기여하는 바가 없는 단어. 예: I, my, me, over
- NLTK에서 100여개 이상의 영어 단어들을 미리 정의
from nltk.corpus import stopwords
5) 정규 표현식 (Regular Expression)
정규 표현식을 이용한 토큰화
from nltk.tokenize import RegexpTokenizer
6) 정수 인코딩 (Integer Encoding)
- 각 단어를 고유한 정수에 맵핑 시키는 전처리
- 빈도수를 기준으로 정렬한 뒤 번호 부여
- NLTK의 빈도수 계산을 위한
FreqEist()참고 tensorflow.keras.preprocessing.text의Tokenizer참고
7) 원-핫 인코딩 (One-hot encoding)
- 단어 집합 (vocabulary): 텍스트의 모든 단어를 중복 허용하지 않고 모은 것
- 원-핫 인코딩: 단어 집합의 단어 수 만큼 크기의 벡터에 나머지 원소는 모두 0이고 특정 단어 지점만 1인 벡터를 원-핫 벡터라고 한다. ex) 단어 집합이
['if', 'elif', 'else']일 때elif의 one-hot vector는[0, 1, 0] tensorflow.keras.utils의to_categorical을 참고
8) 단어 분리하기 (Byte Pair Encoding, BPE)
- OOV (Out-Of-Vocabulary): 단어 집합에 없는 단어, UNK (Unknown Token) 이라고도 함
- OOV 문제: 모르는 단어로 인해 기계가 문제를 제대로 풀지 못하는 상황
- 단어 분리 (subword segmentation): 단어를 여러 단어로 분리해서 단어를 이해해 보려는 전처리 작업
- 단어 분리는 기계가 아직 배운 적이 없는 단어에 대해 어느 정도 대처
- 또 다른 단어 분리 토크나이저 참고: WPM (Wordpiece Model)
- 센텐스피스 (Sentencepiece): 실무에서 사용, 사전 토큰화 작업 없이 raw data를 바로 단어 분리를 할 수 있어서 언어에 종속되지 않음
9) 데이터의 분리 (Splitting Data)
- 머신 러닝 모델에 데이터를 훈련시키기 위해 데이터를 적절히 분리할 필요가 있음
- 지도 학습 (Supervised Learning)에서 Traning data와 Test data를 나누는 것
sklearn.model_selection의train_test_split참고
3. 언어 모델 (Language Model)
언어 모델이란 어떤 단어 시퀀스 (문장) 에 확률을 할당하여 문장이 말이 되는지 확률을 할당하는 모델 또는 가장 자연스러운 단어 시퀀스를 찾아내는 모델
- 통계를 이용한 방법
- 인공 신경망을 이용한 방법
1) 언어 모델이란?
- 언어 모델링이란 주어진 단어들로 부터 아직 모르는 단어를 예측하는 작업
- 언어 모델은 확률을 통해 더 적절한 문장을 판단
- 단어 시퀀스에서 다음 단어가 등장할 확률에 대한 이해 필요
2) 통계적 언어 모델 (Statistical Language Model, SLM)
조건부확률의 연쇄 법칙 (chain rule)
\[P(x_1,x_2,x_3,...,x_n)=P(x_1)P(x_2|x_1)P(x_3|x_1,x_2)...P(x_n|x_1,...,x_{n-1})=\prod_{n=1}^nP(x_n|x_1,...,x_{n-1})\]어떤 문장은 문맥을 통해 이전 단어의 영향을 받아 이후 단어가 파생되므로 특정 문장의 확률은 위 조건부확률과 같다.
카운트 기반 접근
\[P(is|An\space dorable\space little\space boy)=\frac{count(An\space adorable\space little\space boy\space is)}{count(An\space adorable\space little\space boy)}\]카운트 기반 접근의 한계
- 희소 문제 (Sparsity Problem) : 단어가 존재하지 않으면 생기는 문제
3) N-gram 언어 모델 (N-gram Language Model)
아래와 같이 참고하는 단어들을 줄이면 카운트를 할 수 있을 가능성을 높일 수 있다. 4-gram은 다음에 올 단어 예측을 앞의 단어 3개만 고려 \(P(w|boy\space is\space spreading)=\frac{count(boy\space is\space spreading\space w)}{count(boy\space is\space spreading)}\)
n-gram 언어 모델의 한계
- 희소 문제, n선택 trade-off 문제 (n은 최대 5이하 권장)
- 적용 분야에 맞는 copus 수집, 분야에 따라 성능이 달라짐
4) 한국어에서의 언어 모델
한국어에서 언어 모델로 다음 단어를 예측하기 어려운 이유
- 한국어는 어순이 중요하지 않음
- 한국어는 교착어
- 한국어는 띄어쓰기가 제대로 지켜지지 않음
5) 펄플렉서티 (Perplexity, PPL)
- 모델 성능을 평가하기 위해 모델 내에서 성능을 수치화한 내부 평가 (Intrinsic evaluation) 지표
- PPL은 단어의 수로 정규화 (normalization)된 테스트 데이터에 대한 확률의 역수
- PPL은 선택가능한 경우의 수인 분기계수(branching factor)로 언어모델이 특정 시점에서 평균적으로 몇 개의 선택지를 가지고 고민하고 있는지 의미
- 수치가 낮을 수록 고성능
6) 조건부 확률
사건 A가 일어났을 때 사건 B가 일어날 확률을 사건 B의 조건부 확률이라 한다.
\[P(B|A) = \frac{P(A \cap B)}{P(A)}\]사건 A가 일어나는 여부가 사건 B가 일어날 확률에 영향을 미치지 않을 때 사건 A와 B는 서로 독립이라고 한다.
\[P(B|A)=P(B|A^c)=P(B)\]사건 A가 일어나는 여부가 사건 B가 일어날 확률에 영향을 미칠 때 사건 A와 B는 서로 종속이라고 한다.
\[P(B|A) \neq P(B|A^c)\]두 사건 A와 B가 서로 독립이기 위한 필요충분조건
\[P(A \cap B)=P(A)P(B)\]joint probability
\[P(A,B)=P(A \cap B)=P(B|A)P(A)=P(A|B)P(B)\]참고 문헌
4. 카운트 기반의 단어 표현
1) 다양한 단어의 표현 방법
- 단어의 표현 방법 > 단어를 수치화 하는 방법
- 국소 표현 (Local Representation) 방법
- 해당 단어 자체만 보고, 단어를 특정값에 맵핑
- 이산 표현 (Discrete Representation) 이라고도 부름
- 분산 표현 (Distributed Representation) 방법
- 주변을 참고하여 단어를 표현. 단어의 뉘앙스를 표현할 수 있음
- 연속 표현 (Continuous Representation) 이라고도 부름
- 국소 표현 (Local Representation) 방법
2) Bag of Words (BoW)
- 단어 순서는 고려하지 않고 출현 빈도 (frequency)에만 집중
- BoW 만드는 과정
- 각 단어에 고유한 정수 인덱스 부여
- 각 인덱스의 위치에 단어 토큰의 등장 횟수를 기록한 벡터 생성
- BoW는 특정 단어가 얼마나 등장했는지 기준으로 문서가 어떤 성격의 문서인지를 판단하는 작업에 사용
- 분류 문제, 문서간 유사도 구하는 문제
from sklearn.feature_extraction.text import CountVectorizer
3) 문서 단어 행렬 (Document-Term Matrix, DTM)
- 다수의 문서에서 각 단어들의 빈도를 행렬로 표현
- 서로 다른 문서들을 비교할 수 있게 됨
- DTM의 한계
- 희소 표현 (Sparse representation) 이 많아지면 행렬 크기가 방대해짐
- 불용어에 의해 문서 유사도를 잘못 판단 할 수 있음
4) TF-IDF
- 단어 빈도-역 문서 빈도 (Term Frequency-Inverse Document Frequency)
-
DTM 내의 각 단어들마다 중요한 정도를 가중치로 주는 방법
-
주로 사용되는 작업
- 주로 문서의 유사도 구하는 작업
- 검색 시스템에서 검색 결과의 중요도를 정하는 작업
- 문서 내에 특정 단어의 중요도를 구하는 작업
-
계산 방법 (문서는
d, 단어는t, 문서의 총 수n)tf-idf = tf(d,t)*idf(d,t)tf(d,t): 특정 문서 d에서의 특정 단어 t의 등장 횟수df(t): 특정 단어 t가 등장한 문서의 수idf(d,t):df(t)에 반비례하는 수idf(d,t)=log( n/(1+df(t)) )
-
- TF-IDF는 모든 문서가 아닌 특정 문서에서만 자주 등장하는 단어가 중요도가 높다고 판단
from sklearn.feature_extraction.text import TfidfVectorizer
5. 문서 유사도 (Document Similarity)
문서 간의 유사도 성능은 각 문서의 단어들을 어떤 방법으로 수치화 했는지, 문서 간의 단어들의 차이를 어떤 방법으로 계산했는지에 따라 달라진다.
1) 코사인 유사도 (Cosine Similarity)
\[similarity=cos(\theta)=\frac{A \cdot B}{|A||B|}\]- +1: 두 벡터의 방향이 동일
- 0: 두 벡터의 각 90도
- -1: 두 벡터의 방향이 반대
numpy및from sklearn.metrics.pairwise import linear_kernel참고- 유사도 계산을 통한 영화 추천 예제 참고
2) 여러가지 유사도 기법
유클리드 거리 (Euclidean distance) \(\sqrt{\Sigma_{i=1}^n(q_i-p_i)^2}\)
자카드 유사도 (Jaccard similarity) \(J(A,B)=\frac{|A\cap B|}{|A\cup B|}=\frac{|A\cap B|}{|A|+|B|-|A\cap B|}\\ J(doc_1,doc_2)=\frac{doc_1\cap doc_2}{doc_1\cup doc_2}\)
6. 토픽 모델링 (Topic Modeling)
- 문서의 추상적인 주제를 발견하기 위한 통계적 모델
- 텍스트 본문의 숨겨진 의미 구조를 별견하기 위해 사용되는 텍스트 마이닝 기법
1) 잠재 의미 분석
-
잠재 의미 분석 (Latent Semantic Analysis, LSA) 또는 (Latent Semantic Indexing, LSI)
-
LSA 이해를 위해 특이값 분해 (Singular Value Decomposition, SVD) 이해 필요
- $A=U\Sigma V^T$; U=m by m 직교 행렬, V=n by n 직교 행렬, Sigma=m x n 대각행렬
numpy.linalg.svd
-
절단된 SVD (Truncated SVD)
- 하이퍼 파라메터: 사용자가 직접 값을 선택하며 성능에 영향을 주는 매개변수
from sklearn.decomposition import TruncatedSVD
-
U와 V 행렬의 의미
-
U의 행은 문서이고, 열은 토픽. 따라서 각 행은 잠재 의미(토픽)를 수치화한 문서 벡터
-
V의 전치행렬의 행은 토픽이고, 열은 단어. 따라서 각 열은 잠재 의미(토픽)을 수치화한 단어 벡터
-
내 생각: 특정 문서에서 토픽이라 함은 그 문서의 가장 중요한 단어들의 조합을 뽑는 것 (토픽 모델링 예제를 참고할 것)
- LSA 장점
- 쉽고 빠르게 구현
- 단어의 잠재적인 의미를 끌어냄 (내 생각: 단어의 잠재적인 의미가 실체적으로 어떤 것인지 이해가 안감. 토픽과의 상대적 또는 수치적 연관성을 말하는 것인가?)
- 문서 유사도 계산에서 좋은 성능
-
LSA 단점
- 새로운 데이터가 추가되었을 때 처음부터 다시 계산. 즉, 새 정보 업데이트 어려움 > Word2Vec, 인공 신경망 기반 방법론 각광
-
2) 잠재 디리클레 할당
- 잠재 디리클레 할당 (Latent Dirichlet Allocation, LDA)
- LDA의 가정
- 문서들은 토픽들의 혼합
- 토픽들은 확률 분포에 기반하여 단어들을 생성
- 내 생각: 현재까지 읽은 바로는 단어는 기저(basis)와 비슷한 것 같고 토픽은 기저의 선형결합 같은 느낌이다.
- LDA는 LDA 가정을 통해 만들어진 문서 생성 과정을 역으로 추적하여 문서에 어떤 토픽이 들어 있는지 추적하는 역공학 과정
- 잠재 디리클레 할당과 잠재 의미 분석의 차이
- LSA: DTM을 차원 축소하여 축소 차원에서 근접 단어들을 토픽으로 묶음
- LDA: 단어가 특정 토픽에 존재할 확률과 문서에 특정 토픽이 존재할 확률을 결합확률로 추정하여 토픽을 추출
from gensim import corpora,gensim.models.ldamodel.LdaModel- LDA 시각화:
pip install pyLDAvis - 자세한 실습 내용은 책을 참고
3) 잠재 디리클래 할당 (LDA) 실습 2
from sklearn.decomposition import LatentDirichletAllocation
7. 머신 러닝 (Machine Learning) 개요
1) 머신 러닝이란
- 머신 러닝이 아닌 접근 방법의 한계
- 고양이 사진인지 강아지 사진인지 판별하는 일; 이미지 인식 분야
- 머신 러닝은 주어진 데이터로 부터 학습 (training)을 통해 규칙성을 찾는데 초점
2) 머신 러닝 훑어보기
- 머신 러닝을 위한 데이터: 훈련 (Training), 검증 (Validation), 테스트 (Testing)
- 검증용 데이터는 모델의 성능을 조정하기 위한 용도: 과적합, 하이퍼 파라메터 조정
- 회귀와 분류
- 회귀 (Regression): 선형 회귀 (Linear Regression)
- 분류 (Classification): 로지스틱 회귀 (Logistic Regression)
- 이진 분류 (Binary Classification): 합격 불합격, 스팸 메일 분류
- 다중 클래스 분류 (Multi-class Classification)
- 지도 학습과 비지도 학습
- 지도 학습 (Supervised Learning)
- 비지도 학습 (Unsupervised Learning)
- LDA, Word2Vec
- 샘플 (Sample)과 특성 (Feature)
- 혼돈 행렬 (Confusion Matrix)
- 정확도 (Accuracy): 맞춘 문제수를 전체 문제수로 나눈 값
- 혼돈 행렬: 맞춘결과와 틀린결과에 대한 세부적 정보를 알기 위한 행렬
- TP(True Positive), TN(True Negative), FP(False Positive), FN(False Negative)
- 정밀도 (Precision) = TP / (TP + FP), 양성이라고 대답한 전체 케이스에 대한 TP의 비율
- 재현률 (Recall) = TP / (TP + FN), 실제 값이 양성인 데이터의 전체 개수에 대한 TP의 비율
- 과적합 (Overfitting)과 과소 적합 (Underfitting)
- 에포크 (epoch): 전체 훈련 데이터에 대한 훈련 횟수
3) 선형 회귀 (Linear Regression)
- 선형 회귀
- 단순 선형 회귀 분석:
y = Wx+b; W는 가중치(weight), b는 편향(bias) - 다중 선형 회귀 분석:
y=W1x1+W2x2+...+Wnxn+b
- 단순 선형 회귀 분석:
- 가설 (Hypothesis) 세우기
- x와 y의 관계를 유추하기 위한 수학식을 세우는 것
- 비용 함수 (Cost function): 평균 제곱 오차 (MSE)
- 목적 함수 (Object function), 비용 함수 (Cost function), 손실 함수 (Loss function): 실제값과 예측값에 대한 오차에 대한 식
- 평균 제곱 오차 (Mean Squered Error, MSE): W, b -> minimize cost(W, b)
- 옵티마이저 (Optimizer): 경사하강법 (Gradient Descent)
- 옵티마이저를 통해 가장 적절한 W, b를 찾아 나감. W:= W-a*[cost(W)]’
- 위 식에서 a는 alpha인데 학습률 (learning rate)라 부른다.
keras예제 참고
4) 로지스틱 회귀 (Logistic Regression) - 이진 분류
-
시그모이드 함수 (Sigmoid function) \(H(X)=\frac{1}{1+e^{-(Wx+b)}}=sigmoid(Wx+b)=\sigma(Wx+b)\)
-
비용 함수 (Cost function)
-
로지스틱 회귀에서는 로컬 미니멈 때문에 비용함수로 MSE를 사용하지 않음
-
로지스틱 회귀의 크로스 엔트로피 (Cross Entropy) 함수 \(cost(H(x),y)=-[y\space logH(x)+(1+y)log(1-H(x))]\)
-
로지스틱 회귀 목적 함수 \(J(W)=-\frac{1}{n}\Sigma_{i=1}^n[y^{(i)}\space logH(x^{(i)})+(1+y^{(i)})log(1-H(x^{(i)}))]\)
-
-
keras 예제 참고
5) 다중 입력에 대한 실습
- 다중 선형 회귀와 다중 로지스틱 회귀에 대한 keras 예제 참고
- 다중 로지스틱 회귀는 일종의 인공 신경망 구조
6) 벡터와 행렬 연산
- 텐서
- 스칼라: 0차원 텐서, 벡터: 1차원 텐서, 행렬: 2차원 텐서
- 자연어 처리에서 3D 텐서가 자주 등장
- 시퀀스 데이터 표현할 때 (samples/batch_size, timesteps, word_dim)
- 배치(Batch): 훈련 데이터를 여러개 붂어서 한꺼번에 입력으로 사용
- 벡터와 행렬 연산: numpy 사용 예제 참고
- 다중 선형 회귀 행렬 연산으로 이해하기
- 용어: 미니 배치 학습, 배치 크기 (Batch size)
7) 소프트맥스 회귀 (Softmax Regression) - 다중 클래스 분류
-
소프트 맥스 회귀: 3개 이상의 선택지 중에서 1개를 고르는 다중 클래스 분류 문제를 다룸
-
소프트 맥스 함수: 분류해야하는 k개의 클래스에 대한 확률을 추정 \(p_i=\frac{e^{z_i}}{\Sigma_{j=1}^ke^{z_j}}\space for\space i=1,2,...,k\)
-
클래스 분류에 대한 수치 표현은 원-핫 벡터가 적절
-
비용 함수 (Cost function): n개의 전체 데이터에 대한 평균 \(cost(W)=-\frac{1}{n}\Sigma_{i=1}^n \Sigma_{j=1}^k y_j^{(i)}\space log(p_j^{(i)})\)
-
import seaborn as sns -
다중 클래스에 대한 데이터 관찰 예제 및 소프트맥스 회귀 예제를 나중에 다시 볼 것
8. 딥 러닝 (Deep Learning) 개요
1) 퍼셉트론 (Perceptron)
- 프랑크 로젠블라트가 1957년에 제안한 초기 형태의 인공 신경망
- 활성화 함수 (Activation Function): 출력값을 변경하는 함수
- 퍼셉트론에서는 계단함수가 활성화 함수로 사용되었음
- 활성화 함수를 시그모이드 함수로 쓰면 퍼셉트론이 이진 로지스틱 회귀에 해당
- 단층 퍼셉트론 (Single-Layer Perceptron)
- 두 단계로만 구성: 입력층(input layer)과 출력층(output layer)
- 직선 하나로 두 영역을 나눌 수 있는 문제에 대해서만 구현 가능 (AND, NAND, OR)
- 다층 퍼셉트론 (MultiLayer Perceptron, MLP)
- 입력층과 출력층 사이에 은닉층 (hidden layer) 존재
- 단층 퍼셉트론으로는 구현할 수 없었던 XOR 을 구현
- 심층 신경망 (Deep Neural Network, DNN): 은닉층이 2개 이상인 신경망
- 딥 러닝 (Deep Learning): 학습을 시키는 인공 신경망이 심층 신경망일 경우를 말함
2) 인공 신경망 (Artificial Neural Network) 훑어보기
- 피드 포워드 신경망 (Feed-Forward Neural Network, FFNN)
- 다층 퍼셉트론과 같이 입력층에서 출력층 방향으로 연산이 전개되는 신경망
- 순환 신경망 (Recurrent Neural Network, RNN)
- 은닉층의 출력값을 출력층으로도 보내지만, 다시 은닉층의 입력으로 사용
- 전결합층 (Fully-connected layer, FC, Dense layer)
- 어떤 층의 모든 뉴런이 이전 층의 모든 뉴런과 연결돼 있는 층, 밀집층이라고도 부름
- 활성화 함수 (Activation Function)
- 은닉층과 출력층에서 출력값을 결정하는 함수
- 인공 신경망에서 활성화 함수는 반드시 비선형 함수여야 함
- 인공 신경망의 성능을 높이려면 은닉층을 추가해야 하는데, 활성화 함수로 선형 함수를 쓰면 은닉층을 추가해도 1회 추가한 것과 차이가 없음
- 선형층: 활성화 함수가 선형 함수인 층
- 비선형층: 활성화 함수가 비선형 함수인 층
- 인공 신경망의 학습 과정
- 순전파 (forward propagation) 연산
- 순전파 연산을 통해 나온 예측값과 실제값의 오차를 손실 함수 (loss function)로 계산
- 손실 (loss)을 미분을 통해 기울기 (gradient) 계산
- 역전파 (back propagation) 수행
- 시그모이드 함수: 기울기 소실 (Vanishing Gradient) 문제 때문에 은닉층에서 활성화 함수 사용 지양
- 하이퍼볼릭 탄젠트 함수: 기울기 소실 증상이 시그모이드 함수보다 적기 때문에 조금더 많이 사용
- 렐루 (ReLU) 함수: 인공 신경망에서 가장 인기
- 음수를 입력하면 0을 출력하고, 양수를 입력하면 입력값을 그대로 반환. f(x)=max(0,x)
- 특정 값에 수렴하지 않으므로 깊은 신경망에서 시그모이드 함수보다 훨씬 더 잘 작동
- 다른 함수에 비해 연산 속도가 빠름
- 죽은 렐루 (dying ReLU): 입력값이 음수면 기울기가 0이 되어 뉴런 회생이 어려움
- 리키 렐루 (Leaky ReLU)
- 죽은 렐루 보완 위해 입력값이 음수일 경우 0이 아니라 매우 작은 수를 반환. f(x)=max(ax, x)
- 소프트맥스 함수
- 은닉층에서 렐루 함수를 사용하는 것이 일반적이나, 분류 문제에서 출력층에서 적용하여 사용
- 행렬의 곱셈을 이용한 순전파 (Forward Propagation)
- 순전파: 인공 신경망에서 입력층에서 출력층 방향으로 연산을 진행하는 과정
3) 딥 러닝의 학습 방법
- 순전파 (Forward Propagation): 입력층에서 출력층 방향으로 예측값의 연산이 진행되는 과정
- 손실 함수 (Loss function): 실제값과 예측값의 차이를 수치화 해주는 함수
- 회귀: 평균 제곱 오차
- 분류: 크로스 엔트로피
- 옵티마이저 (Optimizer)
- 배치 경사 하강법 (Batch Gradient Descent)
- 한 번의 에포크에 모든 매개변수 업데이트를 단 한 번 수행, 전체 데이터를 고려해서 학습
- 단점: 에포크당 시간이 오래 걸림. 메모리를 크게 요구
- 장점: 글로벌 미니멈을 찾을 수 있음
model.fit(X_train, y_train, batch_size=len(trainX))
- 확률적 경사 하강법 (Stochastic Gradient Descent, SGD)
- 랜덤으로 선택한 하나의 데이터에 대해서만 계산하는 방법
- 단점: 매개변수 변경폭 불안정, 배치 경사 하강법보다 정확도가 낮을 수 있음
- 장점: 속도가 빠름
model.fit(X_train, y_train, batch_size=1)
- 미니 배치 경사 하강법 (Mini-Batch Gradient Descent)
- 정해진 양에 대해서만 계산
- 장점: SGD보다 안정적, 실제로 많이 사용
model.fit(X_train, y_train, batch_size=32)
- 모멘텀 (Momentum)
- 로컬 미니멈에서 탈출하는 효과
keras.optimizers.SGD(lr = 0.01, momentum= 0.9)
- 아다그라드 (Adagrad)
- 변화가 많은 매개변수는 학습률이 작게 설정되고, 변화가 적은 매개변수는 학습률을 높게 설정 시킴
keras.optimizers.Adagrad(lr=0.01, epsilon=1e-6)
- 알엠에스프롭 (RMSprop)
- 나중에 가서 학습률이 지나치게 떨어지는 단점이 있는 아다그라드를 개선
keras.optimizers.RMSprop(lr=0.001, rho=0.9, epsilon=1e-06)
- 아담 (Adam)
- 알엠에스프롭과 모멘텀을 합친 듯한 방법. 방향과 학습률을 모두 잡기 위한 방법
keras.optimizers.Adam(lr=0.001, beta_1=0.9, beta_2=0.999, epsilon=None, decay=0.0, amsgrad=False)
- 배치 경사 하강법 (Batch Gradient Descent)
- 에포크와 배치 크기와 이터레이션 (Epochs and Batch size and Iteration)
- 에포크: 전체 데이터에 대해서 순전파와 역전파가 끝난 상태
- 배치 크기: 매개변수를 업데이트하는 데이터 단위. 전체데이터가 2000이고 배치 크기가 200이라면 배치의 수는 10 (배치의 수를 이터레이션 이라고 함)
- 이터레이션: 한 번의 에포크를 끝내는데 필요한 배치의 수. 즉 매개변수 업데이트 수
3-4) 역전파 (BackPropagation) 이해하기
- 자세한 역전파 예제를 본문에서 참고할 것
- 인공 신경망의 학습은 오차를 최소화하는 가중치를 찾는 목적으로 순전파와 역전파를 반복
4) 과적합 (Overfitting)을 막는 방법들
- 데이터의 양을 늘리기: 데이터 증강 (Data Augmentation)
- 모델의 복잡도 줄이기: 은닉층의 수와 매개변수의 수
- 수용력 (capacity): 인공 신경망에서 모델에 있는 매개변수의 수
- 가중치 규제 (Regularization) 적용하기
- L1 규제: 가중치 w들의 절대값 합계를 비용함수에 추가 (L1 노름)
- 어떤 특성들이 모델에 영향을 주고 있는지를 판단하고자 할 때 유용
- L2 규제: 모든 가중치 w들의 제곱합을 비용함수에 추가 (L2 노름)
- L1 규제의 유용함이 필요없다면 L2 규제가 더 잘 동작. 가중치 감쇠 (weight decay)라 부름
- L1 규제: 가중치 w들의 절대값 합계를 비용함수에 추가 (L1 노름)
- 드롭 아웃 (Dropout)
- 학습과정에서 신경망의 일부를 사용하지 않는 방법
- 예) 드롭 아웃 비율이 0.5 이면 학습 과정마다 랜덤으로 절반의 뉴런만 사용
- 학습 시 특정 뉴런 또는 특정 조합에 너무 의존하는 것을 방지
5) 기울기 소실 (Gradient Vanishing)과 폭주 (Exploding)
- 기울기 소실: 역전파 과정에서 입력층으로 갈수록 기울기가 점차 작아지는 현상
- 기울기 폭주: 기울기가 점차 커져 가중치가 비정상의 큰 값이 되어 발산
- 기울기 소실 또는 폭주 막는 방법
- 은닉층의 활성화 함수로 ReLU, ReLU 변형 사용
- Gradient Clipping: 기울기 폭주시 임계값을 넘지 않도록 값을 자름
- 가중치 초기화 (Weight initialization)
- 같은 모델에 대한 훈련이라도 초기 가중치가 어떤 값이냐에 따라 훈련결과가 달라짐. 따라서 초기 가중치만 적절히 해주도 기울기 소실 문제를 완화
- 세이비어 또는 글로럿 초기화 (Xavier or Glorot initialization): sigmoid 또는 tanh 사용시 효율적
- He 초기화 (He initialization): ReLU 계열 함수 사용시 효율적
- 배치 정규화 (Batch Normalization)
- 인공 신경망의 각 층에 들어가는 입력을 평균과 분산으로 정규화하여 학습 효율을 높임
- 내부 공변량 변화 (Internal Covariate Shift): 신경망 층 사이에서 발생하는 입력 데이터 분포 변화
- 배치 정규화 방법과 여러 장점은 본문을 참고
- 배치 정규화의 한계 역시 본문을 참고
- 층 정규화 (Layer Normalization)
6) 케라스 (Keras) 훑어보기
- Preprocessing
- Tokenizer
- padding: 모든 샘플의 길이를 동일하게 맞추는 작업
- Tokenizer
- Word embedding: 단어를 dense vector로 만드는 작업
- dense vector: 워드 임베딩 과정을 통해 나온 결과. 임베딩 벡터라고도 함
- Modeling
model = Sequential()model.add(Embedding)model.add(Dense)model.summary
- Compile and Training
model.compilemodel.fit
- Evaluation and Prediction
model.evaluatemodel.predict
- Save and Load
model.saveload_model
6-7) 케라스의 함수형 API (Keras Functional API)
- 사용 예를 참고하여 keras sequential API 사용과의 차이를 명확히 해 볼 것
7) 다층 퍼셉트론 (MultiLayer Perceptron, MLP)으로 텍스트 분류하기
keras의Tokenizer.texts_to_matrix- mode:
count,binary,tfidf,freq
- mode:
- 20개 뉴스 그룹을 MLP를 사용하여 텍스트 분류하는 예제를 참고
8) 피드 포워드 신경망 언어 모델 (Neural Network Language Model, NNLM)
- 기계가 자연어를 표현하도록 규칙을 명세하기 어렵기 때문에 주어진 자연어 데이터를 학습하게 하는 방법을 택함!!!!! 생각해 볼 문제
- 피드 포워드 신경망 언어 모델
- 신경망 언어 모델의 시초
- 단어의 유사도 학습
- lookup table, embedding vector
- NNLM 핵심
- 충분한 양의 훈련 코퍼스를 학습하면 유사한 목적으로 사용되는 단어들은 결국 유사한 임베딩 벡터값을 얻게 됨
- 다음 단어를 예측하는 과정에서 훈련 코퍼스에 없던 단어 시퀀스라 하더라도 다음 단어를 선택할 수 있음
- NNLM의 이점과 한계
- 밀집 벡터를 이용한 희소 문제 해결
- n개의 단어만을 참고하여 버려지는 단어들의 문맥 정보를 참고할 수 없음
쉼터: 2020-02-09
여기까지 공부한 후 개념이 너무 방대하고 해깔리기 때문에 XMind를 활용해서 키워드 마인드 맵을 그려보았다.
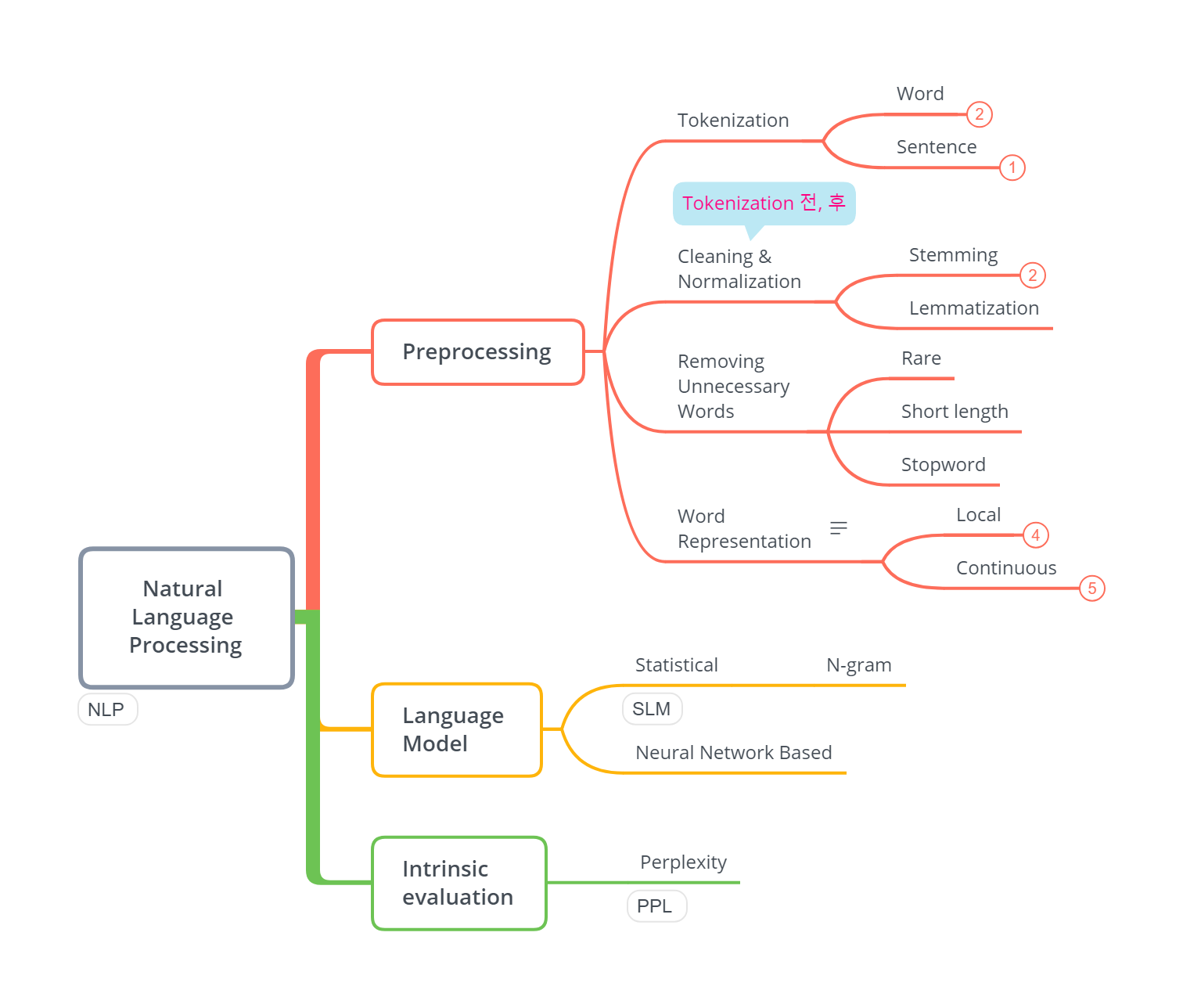
이 후 내용은 잠시 접어두고 다른 TextBook을 공부한 후에 살펴보기로 한다.
Leave a comment